Transactions
Motivation
- Provide atomic operations at servers that maintain shared data for clients
- Provide recoverability from server crashes
Properties (ACID)
- Atomicity
- Consistency
- Isolation
- Durability
Concurrency Control
Motivation
- Without concurrency control, we have lost updates, inconsistent retrievals, dirty reads, etc.
- Concurrency control schemes are designed to allow two or more transactions to be executed correctly while maintaining serial equivalence
- Serial Equivalence is correctness criterion
- Schedule produced by concurrency control scheme should be equivalent to a serial schedule in which transactions are executed one after the other.
Scheme
- Locking
- Optimistic concurrency control
- Time-stamp based concurrency control
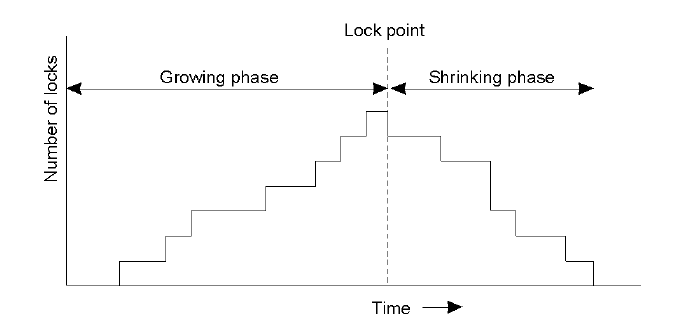
Use of Locks in Strict Two-Phase Locking
When an operation accesses an object within a transaction
- (1) If the object is not already locked, it is locked and the operation proceeds
- (2) If the object has a conflicting lock set by another transaction, the transaction must wait until it is unlocked
- (3) If the object has a non-conflicting lock set by another transaction, the lock is shared and the operation proceeds
- (4) If the object has already been locked in the same transaction, the lock will be promoted if necessary and the operation proceeds
- When promotion is prevented by a conflicting lock, rule 2 is used
Strict Two-Phase Locking
Deadlock
Example
Resolution of Deadlock
Optimistic Concurrency Control
Drawback of locking
- Overhead of lock maintainance
- Deadlocks
- Reduced concurrency
Optimistic Concurrency Control
- In most applications, likelihood of conflicting accesses by concurrent transaction is low
- Transactions proceed as though there are no conflicts
- Three phases
- Working Phase
- Transactions read and write private copies of objects
- Validation phase
- Each transaction is assigned a transaction number when it enters its phase
- Update phase
Validation of Transaction
Timestamp Based Concurrency Control
- Each transaction is assigned a unique timestamp at the moment it starts
- In distributed transactions, Lamport's timestamps can be used.
- Every data item has a timestamp
- Read timestamp = timestamp of transaction that last read the time
- Write timestamp = timestamp of transaction that most recently changed an item
Timestamp ordering write rule
Concurrency Control for Distributed Transactions
- Locking
- Distributed deadlocks possible
- Timestamp ordering
The Two-Phase Commit Protocol

- Problem with two-phase commit
- If coordinator crashes, participants cannot reach a decision, stay blocked until coordinator recovers
- Three-phase commit
- There is no single state from which it is possible to make a transaction directly to another COMMIT or ABORT state
- There is not state in which it is not possible to make a final decision, and from which a transaction to COMMIT can be made.