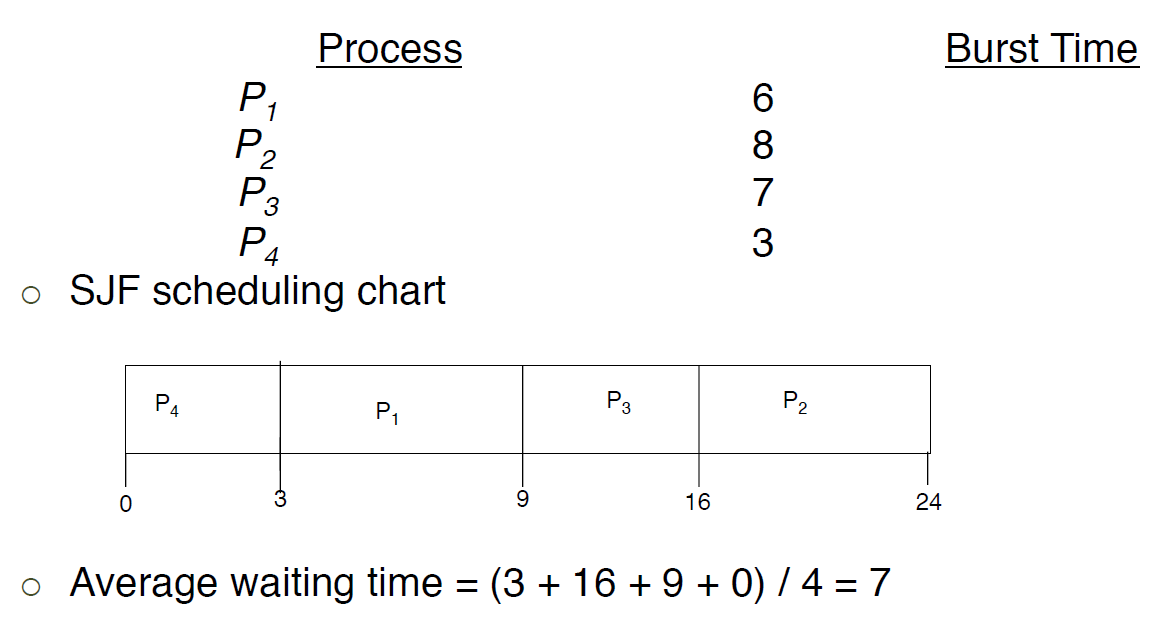
- Program must be brought (from disk) to memory and placed within process for it to be run
- Main memory and registers are only storage CPU can access directly
- Memory unit only sees a stream of addresses + read requests
- or address +data and write request
- Register access in one CPU clock (or less)
- Main memory can take many cycles (stalls)
- Cache sit between main memory and CPU registers
- Protection of memory required to ensure correct operation
2. Address binding
- Addresses represented in different ways at different stages of a program's life
- source code addresses usually symbolic
- compile code addresses bind to relocated addresses
- i.e., 14 bytes from beginning of this module
- Linker or loader will bind relocatable addresses to absolute addresses
- Each binding maps one address space to another
- Address binding of instructions and data to memory addresses can happen at three different stages
- compile time: if memory location known a priori, absolute code can be generated; must recompile code if starting location changes
- load time: must generate relocatable code if memory location is not known at compile time
- execution time: binding delayed until run time if the process can be moved during its execution from one memory segment to another
- need hardware support for address maps (e..g, base and limit registers)
3. Multistep Processing of a user program

4. Logical v.s. Physical Address Space
- The concept of a logical address space that is bound to a separate physical address space is central to proper memory management
- logical address: generated by the CPU; also referred to as virtual address
- physical address: address seen by the memory unit
- Logical and physical addresses are the same in compile-time and load-time address-binding schemes; logical (virtual) and physical addresses differ in execution-time address-binding scheme.
- Logical address space is the set of all logical addresses generated by a program
- Physical address space is the set of all physical addresses generated by a program
5. Dynamic loading
- routine is not loaded until it is called
- better memory-space utilization; unused routine is never loaded
- all routines kept on disk is relocatable load format
- useful when large amounts of code are needed to handle infrequently occurring cases
- no special support from the operation system is required
- implemented through program design
- OS can help by providing libraries to implement dynamic loading
6. Dynamic Linking
- Static linking
- system libraries and program code combined by the loader into the binary program image
- Dynamic liking
- linking postponed until execution time
- small piece of code, stub, used to locate the appropriate memory-resident library rountine
- Stub replaces itself with the address of the routine, and executes the routine
- Operating system checks if routine is in processes' memory address
- if not in address space, add to address space
- Dynamic linking is particularly useful for libraries
- system also known as shared libraries
- Consider applicability to patching system libraries
- versioning may be needed
7. Base and Limit Registers
- A pair of base and limit registers define the logical address space

8. Hardware address protection with base and limit registers

9. Memory Management Unit (MMU)
- Hardware device that at run time maps virtual to physical address
- The user program deals with logical address; it never sees the real physical addresses
- execution-time binding occurs when reference is made to location in memory
- logical address bound to physical address